How AI is learning to convert brain signals into speech

Pixabay
- The technique involves training neural networks to associate patterns of brain activity with human speech.
- Several research teams have managed to get neural networks to “speak” intelligible words.
- Although similar technology might someday help disabled people regain the power to speak, decoding imagined speech is still far off.
Several research groups have recently made significant progress in using neural networks to convert brain activity into intelligible computer-generated speech, developments that could mark some of the first steps toward radically improving the quality of life for people who’ve lost the ability to speak.
As a recent article from Science notes, the groups, which have published several separate papers on the preprint server bioRxiv, aren’t yet able to convert people’s purely imagined words and sentences into computer-generated speech. Still, the teams were successful in getting neural networks to reconstruct words that various participants had either heard, spoken aloud or mouthed silently.
To accomplish that, the teams recorded brain signals and fed them to a neural network, which then matched the signals with associated sounds or mouth movements.
Unfortunately, this kind of work requires opening the skull; researchers need extremely precise data that can only be obtained by surgically implanting electrodes directly onto regions of the brain associated with speech, listening or motor functioning. Making matters more complicated is the fact that each person shows unique neural activity in these regions, so what an AI learns from one person doesn’t translate to the next.
“We are trying to work out the pattern of … neurons that turn on and off at different time points, and infer the speech sound,” Nima Mesgarani, a computer scientist at Columbia University, told Science. “The mapping from one to the other is not very straightforward.”
For the research, the teams relied on participants who were already scheduled to undergo invasive surgery to remove brain tumors or receive pre-surgery treatments for epilepsy.
One team, led by Mesgarani, fed a neural network with data from participants’ auditory cortexes that was obtained while they listened to recordings of people telling stories and listing numbers. Using the brain data alone, the neural network was able to “speak” numbers to a group of listeners who were able to identify the digits correctly about 75 percent of the time.
Another team, led by neurosurgeon Edward Chang and his team at the University of California, San Francisco, recorded epilepsy patients’ brain activity as they read sentences aloud, and fed the data to a neural network. A separate group of people then listened to the neural network’s attempts to reconstruct the sentences, and after selected from a written list which sentences they thought it was trying to reproduce. In some cases, they chose correctly 80 percent of the time.
Chang’s team also managed to get a neural network to reproduce words that participants had only mouthed silently, an achievement that marks “one step closer to the speech prosthesis that we all have in mind,” as neuroscientist Christian Herff at Maastricht University in the Netherlands told Science.

A scene from The Diving Bell and the Butterfly (2007).
Deciphering imagined speech
The techniques described above work because neural networks were able to find patterns between two relatively defined sets of data: brain activity and external speech functions (such as spoken words or mouth movements). But those external functions aren’t present when someone merely imagines speech, and, without that data to use for training, it’s unclear whether neural networks would ever be able to translate brain activity into computer-generated speech.
One approach, as Herff told Science‘s Kelly Servick, involves giving “feedback to the user of the brain-computer interface: If they can hear the computer’s speech interpretation in real time, they may be able to adjust their thoughts to get the result they want. With enough training of both users and neural networks, brain and computer might meet in the middle.”
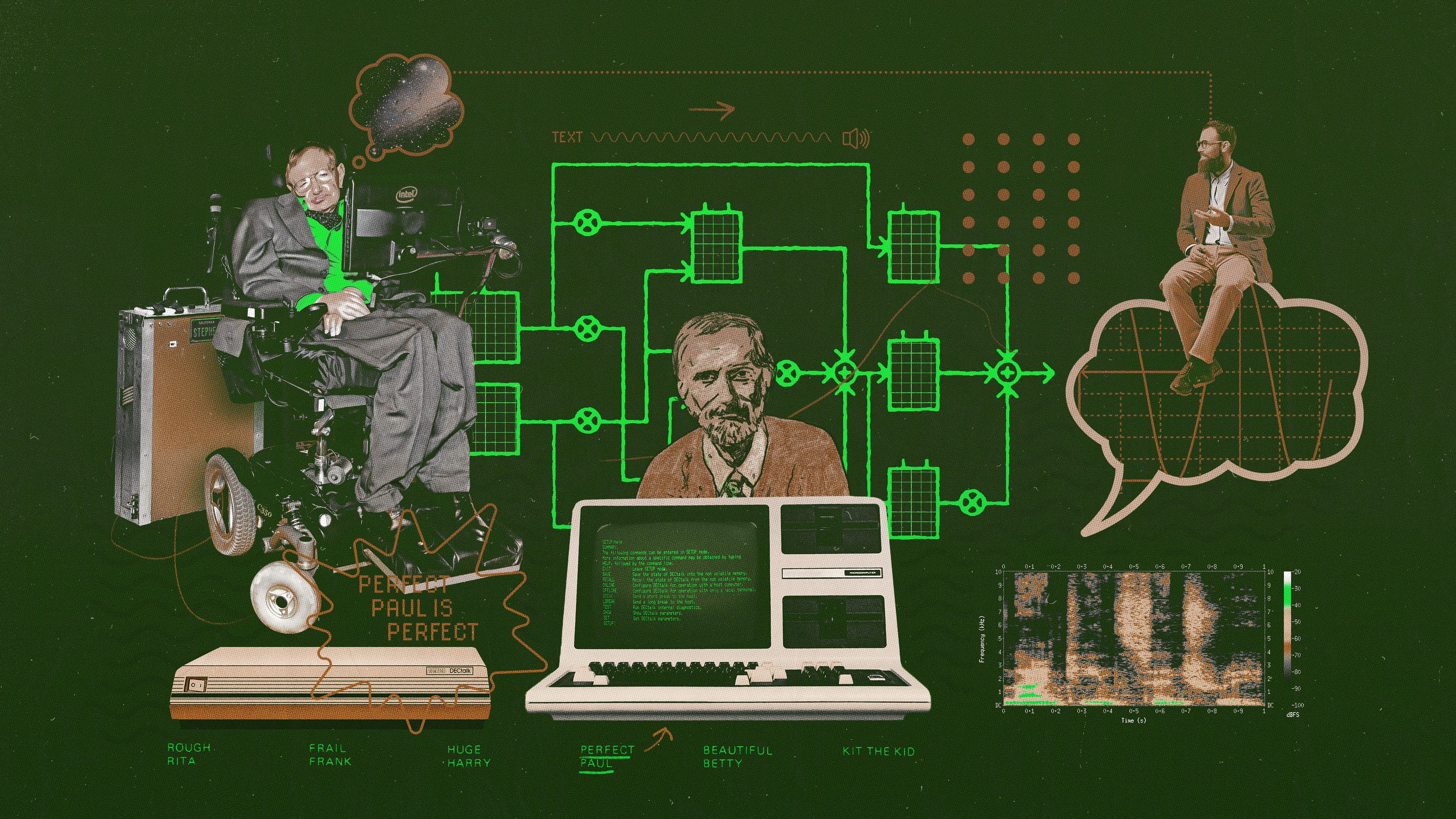
It’s still speculative, but it’s easy to see how technology of the sort could greatly improve the lives of people who’ve lost the ability to speak, many of whom rely on speech-assist technology that requires people to make tiny movements in order to control a cursor that selects symbols or words. The most famous example of this is the system used by Stephen Hawking, who described it like this:
“My main interface to the computer is through an open source program called ACAT, written by Intel. This provides a software keyboard on the screen. A cursor automatically scans across this keyboard by row or by column. I can select a character by moving my cheek to stop the cursor. My cheek movement is detected by an infrared switch that is mounted on my spectacles. This switch is my only interface with the computer. ACAT includes a word prediction algorithm provided by SwiftKey, trained on my books and lectures, so I usually only have to type the first couple of characters before I can select the whole word. When I have built up a sentence, I can send it to my speech synthesizer. I use a separate hardware synthesizer, made by Speech Plus. It is the best I have heard, although it gives me an accent that has been described variously as Scandinavian, American or Scottish.”