No, LLMs still can’t reason like humans. This simple test reveals why.

- Large language models are the bleeding edge of AI technology, yet they regularly answer simple questions wrong.
- Philip L of AI Explained has created a performance benchmark for how LLMs’ reasoning capabilities called “Simple Bench.”
- In this article, Philip explains why LLMs score significantly worse than humans on the test and why we should recognize these shortcomings.
Imagine what would happen if you attempted the following experiment: First, place a washed, fresh tomato and an equally clean carrot on top of a normal kitchen plate. With one hand behind your back, flip the non-stick plate upside-down, inspecting the underside of the plate for marks. Now, slowly turn the plate right-side up and count the number of vegetables remaining on top. How many are on the plate?
I’d expect you to answer “zero.” To get that answer, you almost certainly did not actually conduct the experiment but rather simply visualized what would happen: two items dropping onto your kitchen floor. The scenario is so simplistic that you’re likely wondering why I’d ask you about it in an article ostensibly about bleeding-edge artificial intelligence.
The thing is, large language models (LLMs) often get questions like this wrong. Before you rush off to test GPT-4o and Claude 3.5 Sonnet (leading LLMs from OpenAI and Anthropic, respectively), here is some exact wording to try:
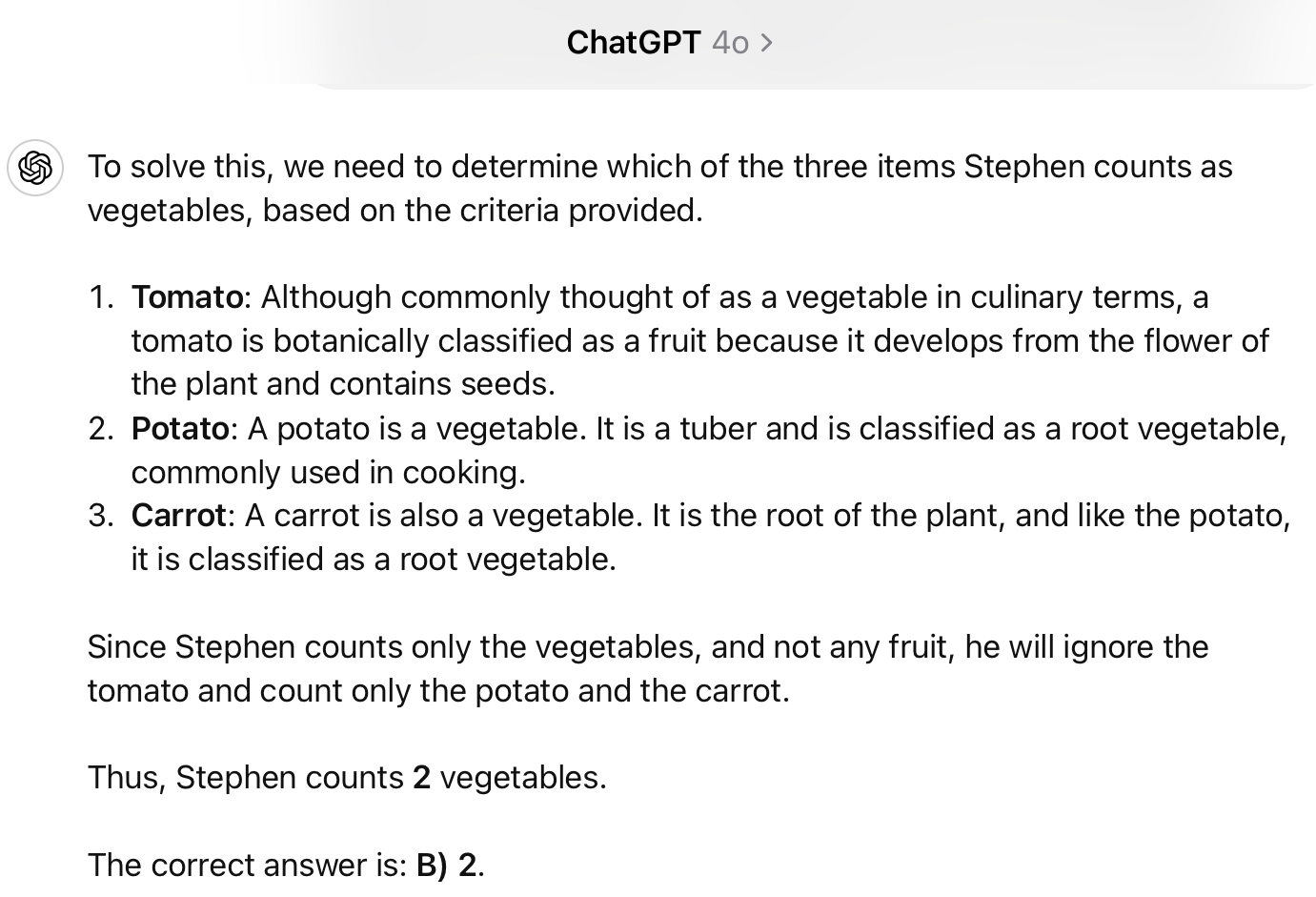
“Stephen carefully places a tomato, a potato, and a carrot on top of a plate. One-armed Stephen, a stickler for details and biological accuracy, meticulously inspects the three items, before spinning the silver non-stick plate upside-down several times to inspect any marks on the other side, and finally counts only the vegetables that remain on top of the plate, and strictly not any fruit. How many vegetables does Stephen realistically count? A) 3 B) 2 C) 1 D) 0?”
As of this writing (and before the models become trained on the exact text of this article), both GPT-4o and Claude 3.5 Sonnet get this question wrong, generally picking B or C. So do models from all other model families, like Llama 3.1 and Google Gemini.
But wait! According to some, these models — or even their precursors — are already artificial general intelligences! They are said to threaten hundreds of millions of jobs, if we listen to Goldman Sachs, and could affect up to 40% of all advanced-economy jobs, according to the International Monetary Fund. There are warnings aplenty of the threat that AI poses to the continued existence of humanity.
This is not to say that any of those warnings are false, or that LLMs represent the totality of “AI.” It’s more to underline the surprise you might feel that “frontier models” fail such a simple question.
So why do they screw up, and can we measure such failures more quantitatively?
Simple Bench
Well, let me answer my own two questions in reverse order. First, how should we quantify the magnitude of these blindspots? One way is to establish a performance benchmark by evaluating how LLMs respond to hundreds of carefully crafted questions, which I’ve begun doing through a new project called “Simple Bench.”
On the site, you can see the current performance of top models, try a couple more questions yourself, and learn a bit more about the effort. The rest of the questions are fully private, to prevent models from simply memorizing answers, as they are suspected to have done on many other popular benchmark tests.
The vegetable question above is just one example in a broad category of failure, which we could call a failure of spatial reasoning: not reliably understanding that objects will fall off a plate if nothing is holding them in place. Other failure categories include temporal reasoning, where models have little sense of how long things take, and social intelligence, which requires an intuition about how humans would likely behave in basic social situations.
Simple Bench doesn’t just test the occasional embarrassing blip, which can be updated away in a fine-tuning jiffy. It’s also not the cheap trick of exposing the model’s inability to “see” the actual characters in the words of a question (a tokenization issue that explains the embarrassing proclivity of LLMs to miscount the number of “r”s in “strawberry,” or slip up on the question, “Which number is bigger: 9.11 or 9.9?”).
Simple Bench is also not about testing a model’s ability to code or use an external tool. For sure, a model might screw up when asked 4^4^4, but large language models aren’t natural calculators; they’re generally getting better at deploying code to perform these kinds of computations. Plus, it’s a bit low to castigate its failure to work out 4^4^4, when you or I wouldn’t have a hope of calculating it ourselves without some tools, like a pen. (A quick tangent: I did once correctly calculate 1,879,602^2 in my head; I was very bored, it took me an hour, and it was a while ago, but that’s cool, I think.)
Instead, Simple Bench is different from most traditional machine learning benchmarks, and certainly better than most of the recent LLM reasoning benchmarks, in that the average person can actually get most questions right.
As of this writing, among the handful of people to whom I have given the full suite (who are admittedly more motivated and curious individuals than average), the average score has been 92%. The best-performing LLM so far has been Claude 3.5 Sonnet, scoring 27%.
That’s definitely not nothing. I’ve been quite impressed at the faint flickers of proto-world modeling occurring within language models. It could well be that when equipped with verifiers (models that internally review the reasoning steps of an output before it is submitted), performance could noticeably improve.
But the gap in performance between humans and current large language models on Simple Bench is a far cry from what many headlines would lead you to expect.
So, what explains the shocking failures of basic reasoning that Simple Bench exposes? Let’s return to the vegetables — or fruits and vegetables, if you wish. Here’s my take on the first of my two questions: Why do models fail the question you saw above?
LLMs don’t model reality
The clue is in their name: language models. They model language. When triggered with phrases such as “Stephen, a stickler for facts and scrupulous biological accuracy,” and “counts only the vegetables that remain on top of the plate, and strictly not any fruit,” their attention centers on whether we should count a tomato as a fruit or vegetable. (I won’t wade into that culinary debate, by the way, and it doesn’t affect the correct answer to this question, which is zero regardless of what is a vegetable.)
A language model cannot just simulate the scenario mentioned above or “visualize” it like we can. It is easily tricked into focusing on what are, objectively, less important details. It also has no way of ranking what is “important” in a scenario, other than in how it affects the prediction of the next word/token.
Language models model language, not reality. Their goal is to predict the next word, not the next consequence of a cause-and-effect chain. Because so much of physics and reality is at least partially reflected in language — and so many experiments and basic facts are fossilized in easily memorized textbooks — models can perform shockingly well on naive tests of their ability, like university exams.
But when they are taken out of their comfort zone — when we go where language has not trodden before, and when the wording is no straightforward guide to the answer — they get stuck. Reliably so. Hilariously so, in many cases.
Language models model language, not reality. Their goal is to predict the next word, not the next consequence of a cause-and-effect chain.
Language modeling is an incredible feat, and my total general knowledge would appear as a complete joke if ChatGPT were somehow to form an opinion of it. It’s also highly unlikely that the march to AGI will only follow the naive path of simply scaling up LLMs and expecting miracles.
To be sure, Simple Bench is not finished. I’m certain there are many more common failure modes to explore, and I hope Simple Bench will be useful for those businesses testing new approaches for AI reasoning, including custom models, AI agents, and novel prompting strategies. Data derived from the almost endless failures that are being found could help augment the training data of new models.
But I do believe that Simple Bench exposes a general truth about LLMs that has at times completely slipped off the plate of our collective attention.
Philip is the creator of the AI Explained YouTube channel. He also runs AI Insiders, a community of more than 1,000 professionals working in generative AI across 30 industries, and authors the newsletter Signal to Noise.
This article was originally published by our sister site, Freethink.
![]()