Google’s ‘Translatotron’ translates your speech while retaining the sound of your voice
Omegatron via Wikipedia
- Current translators break down the translation process into three steps, based on converting the speech to text.
- The new system uses machine learning to bypass the text representation steps, converting spectrograms of speech from one language into another language.
- Although it’s in early stages, the system can reproduce some aspects of the original speaker’s voice and tone.
Google’s Translatotron is a new translation system that could soon be able to translate your speech into another language without losing key aspects of your voice and tone. The system is still in its early stages, but you can get an idea of how the technology might sound by listening to the audio samples below (around the 1:00 mark).
It’s not a perfect reproduction, but Google suggests its new system could soon provide a far more seamless translation experience than current translators.
Such systems, like Google Translate, break down the translation process into three steps, as Google wrote in a blog post: “automatic speech recognition to transcribe the source speech as text, machine translation to translate the transcribed text into the target language, and text-to-speech synthesis (TTS) to generate speech in the target language from the translated text.” The result is that your spoken words are converted to text, that text is converted into a different language, and then machine intelligence speaks your words in a different language.
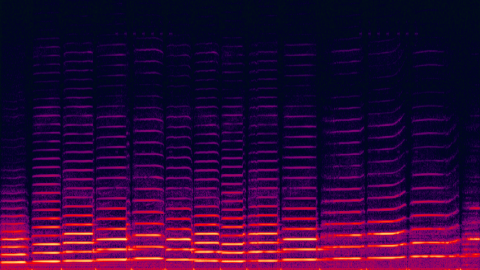
Translatotron is different because it bypasses the intermediate text representation steps. Google accomplishes this by using a neural network to convert spectrograms of speech from one language into another language. (Spectrograms are visual representation of the spectrum of frequencies in a sound.)
“It makes use of two other separately trained components: a neural vocoder that converts output spectrograms to time-domain waveforms, and, optionally, a speaker encoder that can be used to maintain the character of the source speaker’s voice in the synthesized translated speech,” Google wrote in its blog post.
Google added that its new approach brings several advantages, including:
“. . . faster inference speed, naturally avoiding compounding errors between recognition and translation, making it straightforward to retain the voice of the original speaker after translation, and better handling of words that do not need to be translated (e.g., names and proper nouns).”
Google is still working out the kinks in Translatotron (you can check out some of the system’s less impressive translation efforts here.) But it’s not hard to see how Translatotron could soon make foreign-language interactions run more smoothly, by capturing and reproducing some of the nuances that get lost when a robotic voice synthesizes text into speech.